Like everyone in the tech industry, I’ve been trying different Generative AI tools for coding in the last few months, from Cursor to Warp and more. We have seen a lot of discussions about the security, performance, and correctness of AI-generated code. Ultimately, the consensus around these problems is that as models improve in quality, their correctness will too, but for the time being, humans are still responsible for checking all the generated code before putting it up for review in a pull request and deploying it.
As someone who has been working primarily on improving developer productivity for the last couple of years, I spend most of my time trying to reduce build times, speed up CI builds, and make builds more deterministic and efficient for engineers. For this reason, a particular area I’m interested in is how AI coding agents and tools affect developer infrastructure.
The term developer infrastructure here can include many systems that developers interact with and experience on a daily basis, such as a build system, code hosting service, CI system, deployment tooling, and more.
Cursor claims that it’s used by 53% of the Fortune 1000 companies and that 100M+ lines of enterprise code are written per day (from Cursor’s enterprise page). This scale and speed of adoption is very exciting for anyone focused on developer productivity.
I have spent the last 7 or so years (and still do) enabling engineers to be more productive in different ways. If you’ve ever worked in a platform/developer productivity organization, you might be very familiar with this role. Whether your task involves moving code to a more efficient build system (such as Bazel) or changing decade-old development strategies into more efficient workflows, you never run out of work. In order to help your decision-making process, you are likely tracking metrics such as local or CI build times. If you have more instrumentation and resources available, you might even be able to estimate the time it takes to go from an idea to shipping it to production. These metrics can help evaluate how effective your tools are at accelerating development.
With the recent industry-wide push to make engineers more efficient, it’s a natural task for platform organizations to invest in researching and recommending new workflows and tools to improve the engineering experience. Some examples of this work might include working with a security team to approve new tools, generating Cursor rules to make sure that every model has the right context for complex codebases and wrapping tools or models with custom integrations to suit specific needs.
Many companies working at scale have invested years and many engineers in improving their developer productivity to better support the growing scale of their codebases even before AI coding tools were available. Google, Meta, and Microsoft are the famous examples of investing and building custom tooling to support hundreds of millions of lines of code (LoC) that need maintenance and deployments every day. Other tech companies which might reach tens of millions of lines of code have also been on similar paths to aim first to reuse existing (open-source, SaaS, etc.) software to improve their developer experience and speed of iteration. For example, many companies in this group use some sort of software or open-source tool maintained by the above companies (think about Google Cloud, AWS, GitHub, Bazel, etc.).
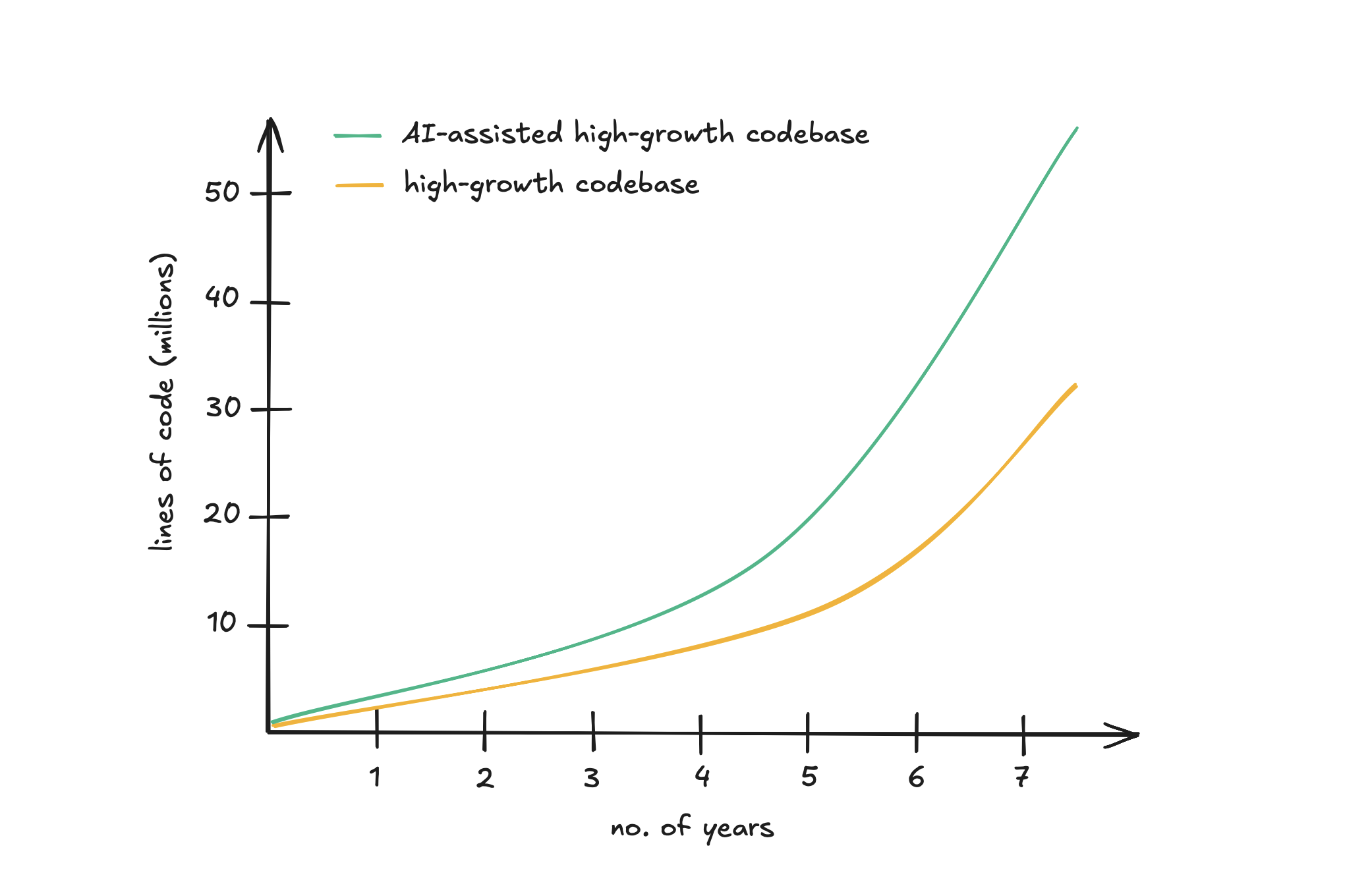
High-growth company codebases often increase by 30% YoY in LoC. This means that a project which starts with 1 million LoC at year 1, might grow to over 3.7 million LoC 5 years later. 10 years later? 13.7 million LoC. 20 years later? 190 million LoC. You get the point. This is how Google ended up with an approximate 2 billion LoC in 2015.
Since we are still in the early days of coding agents and deploying tools like Cursor to a very wide population of engineers, I haven’t seen any research in this area to try to predict how much software projects will grow in terms of lines of code, build times, and all the struggles that usually come with a very big codebase due to AI coding agents.
One example of this possible increase in code growth in software projects is the simple process of writing tests. LLMs are great at writing tests but sometimes they can be too eager to cover all edge cases. That’s likely something that humans are lazier about (for the better or worse). The testing team in your company might suddenly be very happy to see the code coverage reach historic highs in your codebase, while the continuous integration team might not be so happy to suddenly need to support a much higher number of tests being added to the codebase every week which might contribute to a drastic increase in continuous integration times and flakiness.
One real-life example of this was highlighted in “Real-world engineering challenges: building Cursor” by The Pragmatic Engineer which revealed the following (shortened and paraphrased):
Cursor has 50 engineers. The 3-year-old codebase is 7 million LoC across 25,000 files. 50% of the code was generated by AI.
It looks like Cursor already has more lines of code than a Boeing 787.
It would be very interesting to know the breakdown of Cursor’s codebase and historical growth to better understand the effect of its own product on its internal development. How to answer the question “How many LoC does your product have?” could take another full blog post (do you include third-party dependencies? Do you include tests?), so I suggest taking this number with a grain of salt and not consider it too much, but it’s a very interesting insight regardless.
The Cursor IDE itself is likely the most prominent product with the most AI contributions so far. The engineers used the IDE to build many of its features (very meta), so this is likely the first signal of what future products built with AI support might look like.
Whether you want it or not, software projects are about to get bigger way faster than before thanks to AI-generated code. If the developer infrastructure for your project already handles tens or hundreds of millions of lines of code just fine, the addition of AI-generated code shouldn’t be too noticeable. If instead your project is already quickly growing and it’s on the verge of encountering new scaling issues, the quick addition of AI-generated code might finally tip you over to a whole new category of challenges.
If you work in a platform team or even if you don’t but you still care about the scalability of your products and teams, here’s a question that you can start thinking about to prepare for the future AI-assisted coding world: can your current developer infrastructure support a 2–3x increase in codebase size?
If the answer is “No”, “Maybe” or even “No idea”, here are some topics you might want to start trying to answer and investigate:
- Do your build and continuous integration systems support caching or distributed execution? This is usually the biggest bottleneck in codebases that grow very quickly without a platform team supporting them.
- How modularized are your services and applications? Think about the effects of a drastic increase in lines of code, number of modules and tests from an architectural point of view.
- How do your development environments handle flakiness in builds and tests? If you already have a small project with only 10 tests that have 0.1% flakiness and your current solution is simply retriggering builds manually, when your project will contain 1000 tests with the same 0.1% flakiness, you will likely need a different solution.
- Do you have clear guidelines for engineers on how to review AI-generated code? How do you ensure it follows long-standing team conventions? Whether code is generated or human written, you want it to be consistent.
If you are already collecting metrics such as code growth (lines of code, number of modules, tests, etc.) along with build and test times, and the majority of your teams are using AI for code assistance, I would be curious to hear if you have found any interesting effects. If you are not tracking these metrics just yet, I suggest you start doing so very soon.
We likely need to wait a few more months (or even years) of using AI coding tools with agentic capabilities (such as Cursor, which can generate much larger chunks of code) before we fully understand their impact on code growth and developer infrastructure. For now, all we can do is sit back, continue improving our developer infrastructure to prepare for even bigger codebases, make sure we provide our LLMs with the right context and rules, and educate engineers on reviewing and verifying all generated code. All of this should help us keep the cognitive debt to a minimum.
If you’re interested in more topics around AI, developer productivity, and platform tools, let me know and I’ll be happy to chat.